General Architecture of LVS Clusters
For transparency, scalability, availability and manageability of the whole system, we usually adopt three-tie architecture in LVS clusters illustrated in the following figure.
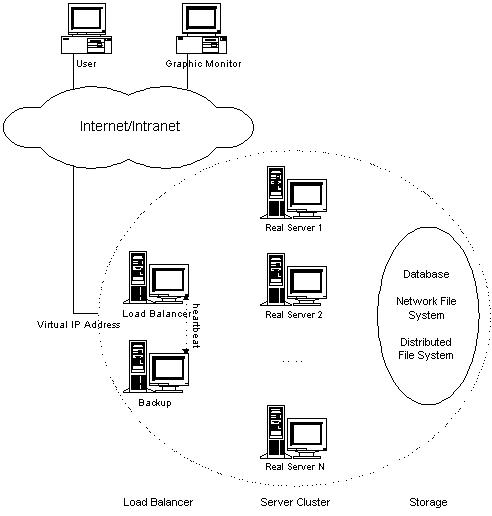
The three-tie architecture consists of
- Load Balancer, which is the front-end machine of the whole cluster systems, and balances requests from clients among a set of servers, so that the clients consider that all the services is from a single IP address.
- Server Cluster, which is a set of servers running actual network services, such as Web, Mail, FTP, DNS and Media service.
- Shared Storage, which provides a shared storage space for the servers, so that it is easy for the servers to have the same contents and provide the same services.
Load balancer is the single entry-point of server cluster systems, it can run IPVS that implements IP load balancing techniques inside the Linux kernel, or KTCPVS that implements application-level load balancing inside the Linux kernel. When IPVS is used, all the servers are required to provide the same services and contents, the load balancer forward a new client request to a server according to the specified scheduling algorithms and the load of each server. No matter which server is selected, the client should get the same result. When KTCPVS is used, servers can have different contents, the load balancer can forward a request to a different server according to the content of request. Since KTCPVS is implemented inside the Linux kernel, the overhead of relaying data is minimal, so that it can still have high throughput.
The node number of server cluster can be changed according to the load that system receives. When all the servers are overloaded, more new servers can be added to handle increasing workload. For most Internet services such as web, the requests are usually not highly related, and can be run parallely on different servers. Therefore, as the node number of server cluster increases, the performance of the whole can almost be scaled up linearly.
Shared storage can be database systems, network file systems, or distributed file systems. The data that server nodes need to update dynamically should be stored in data based systems, when server nodes read or write data in database systems parallely, database systems can guarantee the consistency of concurrent data access. The static data is usually kept in network file systems such as NFS and CIFS, so that data can be shared by all the server nodes. However, the scalability of single network file system is limited, for example, a single NFS/CIFS can only support data access from 4 to 8 servers. For large-scale cluster systems, distributed/cluster file systems can be used for shared storage, such as GPFS, Coda and GFS, then shared storage can be scaled up according to system requirement too.
Load balancer, server cluster and shared storage are usually connected by high-speed networks, such as 100Mbps Ethernet network and Gigabit Ethernet network, so that the network will not become the bottleneck of system when the system grows up.